La partie d'Expresso qui fournit la gestion des tâches, la gestion du temps et des communications entre tâches ne dépend pas du hardware. Cette section explique en détail les services offerts par le système d'exploitation ainsi que leurs fonctionnements. Nous allons étudier successivement la gestion des tâches, la politique d'ordonnacement, la gestion du temps et les mécanismes de communications entre tâches offert par Expresso.
Du point de vue utilisateur, une tâche est une fonction qui effectue un certain travail. Lorsqu'on a un problème avec des
contraintes temps-réel à résoudre, il faut séparer le problème en un ensemble de tâches. Chaque tâche ayant pour rôle de traiter
une partie du problème.
Plus précisément, une tâche est soit une fonction qui contient une boucle infinie, soit une fonction qui se supprime elle-même
quand elle s'est exécutée. Quand une tâche est supprimée, en fait le code n'est pas supprimé de la mémoire mais le scheduler
ne tient plus compte de cette tâche (état DORMANT). Une tâche ressemble à une fonction C avec une type de retour et des arguments
mais elle ne renvoie jamais son type de retour. Le type de retour est toujours déclaré void.
Il faut décider si le nombre maximum de tâches est fixé ou non. Si on le fixe, le choix de la tâche de plus haute
priorité devient relativement rapide mais un peu moins flexible. Si on laisse varier le nombre maximum de tâches, on
complexifie grandement la détermination de cette tâche de plus haute priorité.
Nous verrons cela en détail plus tard, mais la caractéristique fondamentale de l'ordonnacement est son déterminisme. Le déterminisme intervient lors de la recherche de la tâche de plus haute priorité. Il faut arriver à faire ce calcul en un temps constant ce qui est très difficile si on laisse varier le nombre de tâches. Pour toutes ces raisons, Expresso peut gérer un maximum de 64 tâches, ce qui est suffisant pour des applications temps-réel habituelles. Expresso crée une tâche idle qui est exécutée quand aucune autre tâche n'est exécutable. Le nombre de tâches système (pour l'instant uniquement la tâche idle) est représenté par la constante SYS_TASKS et le nombre de tâches utilisateur par MAX_TASKS donc :
Maintenant, il faut choisir entre des priorités uniques ou pas. Si plusieures tâches peuvent avoir la même priorité, la
détermination de la tâche de plus haute priorité est plus compliquée et doit suivre une politique spéciale (FIFO, round-robin, etc).
Expresso attribue une priorité unique à chaque tâche, ce qui n'enlève rien aux possibilités offertes par le système. La priorité peut
varier entre 0 et LOWEST_PRIO. Plus le numéro de la priorité est faible plus la priorité est élevée. La tâche idle a la
priorité LOWEST_PRIO.
Pour exécuter son code, chaque tâche doit aussi contenir une pile. C'est sur cette pile que les données utilisées par la tâche
seront stockées.
Voyons en détail la structure d'une tâche (T_TASK). Chaque tâche contient :
Expresso offre les services suivants concernant les tâches :
Pour effectuer cela, nous avons besoin de quelques structures :
La fonction createTask() permet de créer une tâche. Une tâche peut être créée avant le démarrage du multitâche ou
par une autre tâche. Il faut évidemment créer au moins une tâche avant de démarrer le multitâche mais ceci est fait automatiquement
par le scheduler qui crée la tâche idle. La fonction createTask a le prototype suivant :
| INT8U createTask(void (*task)(void *pd), void *pdata, STK *ptos, INT8U prio) | |
| Arguments : | |
| - task : le pointeur vers le code de la tâche | |
| - pdata : le pointeur vers des données que l'on passe à la tâche quand elle | |
| commence son exécution. | |
| - ptos : un pointeur vers le sommet de la pile de la tâche. | |
| - prio : la priorité désirée de la tâche | |
| Valeur de retour | |
| - ERROR_PRIO_INVALID : priorité invalide | |
| - ERROR_PRIO_EXIST : la priorité existe déjà | |
| - ERROR_NO_MORE_TASK : plus aucune tâche libre | |
| - NO_ERROR : aucune erreur | |
La fonction createTask commence par vérifier que la priorité désirée est valide, càd qu'elle est comprise dans l'intervalle
[0, LOWEST_PRIO]. On désactive les interruptions. Ensuite, il faut vérifier que la priorité désirée n'est pas déjà prise par une
autre tâche, car les priorités sont uniques et donc 2 tâches ne peuvent pas avoir la même priorité. Si la priorité est libre, on
la réserve et on peut activer à nouveau les interruptions, car le remplissage du descripteur de la tâche ne nécessite pas un
blocage des interruptions.
Ensuite, il faut initialiser la pile de la tâche. Pour cela on va appeler la fonction stackInit. Cette fonction
est spécifique au processeur et initialise la pile de la tâche (voir Fig ![]() )en placant les valeurs suivantes :
)en placant les valeurs suivantes :
Il reste à initialiser le descripteur de la tâche et à modifier les pointeurs. On commence par prendre la première tâche dans la liste des tâches libres freeTaskList et on met a jour cette liste. Il faut insérer un pointeur vers le descripteur dans taskCreated, puis insérer la tâche dans la liste des tâches taskList. Pour terminer, on rend la tâche exécutable et on fait un appel à la fonction scheduler() pour relancer l'ordonnanceur.
La fonction deleteTask() permet de supprimer une tâche.
| INT8U deleteTask(INT8U prio) | |
| Arguments : | |
| - prio : la priorité de la tâche à supprimer | |
| Valeur de retour | |
| - ERROR_PRIO_INVALID : priorité invalide | |
| - ERROR_DEL_IDLE : impossible de supprimer la tâche idle | |
| - ERROR_DEL_ISR : impossible de supprimer une tâche depuis une interruption | |
| - ERROR_DEL : la tâche de cette priorité n'existe pas | |
| - NO_ERROR : aucune erreur | |
Pour supprimer une tâche, il faut d'abord vérifier que la priorité soit inférieure à LOWEST_PRIO et que l'on ne se trouve pas dans une interruption. On vérifie ensuite que la tâche existe et on la supprime de la liste des tâches pour l'insérer dans la liste des tâches libres. Pour terminer, on fait appel à scheduler() pour forcer l'ordonnanceur à exécuter la tâche de plus haute priorité.
| INT8U changeTaskPriority(INT8U oldPrio, INT8U newPrio) | |
| Arguments : | |
| - oldPrio : l'ancienne priorité de la tâche | |
| - newPrio : la nouvelle priorité | |
| Valeur de retour | |
| - ERROR_PRIO_INVALID : priorité invalide | |
| - ERROR_PRIO_EXIST : la tâche de priorité newPrio existe déjà | |
| - ERROR_PRIO : la tâche de priorité oldPrio n'existe pas | |
| - NO_ERROR : aucune erreur | |
Pour changer la priorité d'une tâche, il faut d'abord vérifier que les deux priorités oldPrio et newPrio sont
inférieures à LOWEST_PRIO. On vérifie ensuite que la nouvelle priorité est libre sinon on renvoie ERROR_PRIO_EXIST
et on vérifie que l'ancienne priorité correspond bien à une tâche sinon on renvoie ERROR_PRIO. Ensuite si la tâche était
exécutable, on l'enlève des tâches exécutables et on insère la nouvelle priorité dans la liste des tâches exécutables. On vérifie
que cette tâche n'est pas en attente sur une ITC sinon on appelle itcChangePrio (voir plus loin). Ensuite, on met à jour
le descripteur avec la nouvelle priorité et on insère le descripteur au bon endroit dans la table taskCreated. Pour finir,
on fait appel à scheduler().
Il faut faire attention en utilisant cette fonction car si une tâche (T1) change la priorité d'une autre tâche (T2), la référence
que d'autres tâches pouvaient avoir de (T2) est perdue. La solution serait de séparer la priorité de l'identifiant d'une tâche.
Pour être complet, il reste deux petites fonctions :
Expresso implémente un ordonnancement préemptif. A chaque instant c'est donc la tâche de plus haute priorité exécutable qui est exécutée. Une caractéristique fondamentale est que l'ordonnaceur soit déterministe, il faut donc pouvoir déterminer quelle est la tâche la plus prioritaire en un temps constant et cela quelle que soit le nombre de tâches présentes dans le système. Tous les services offerts par Expresso, sauf la fonction pour mettre à jour les tâches temporisées, sont indépendants du nombre de tâches. Nous reviendrons sur cette fonction dans la partie sur la gestion du temps.
Il faut une structure de données qui nous permette de trouver l'information en un temps constant et de préférence en peu
d'opérations. Toutes les structures en arbre, table hash, liste liées, etc sont à proscrire car elles dépendent intrinsèquement
du nombre de tâches présentes dans le système. La structure la plus appropriée est une table avec une taille fixe, cette taille
est le donnée par le nombre de tâches maximum pouvant être gérées par le système. MicroC/OS [#!MicroC_OS-II!#] utilise une
structure parfaite pour cela, nous avons repris cette structure dans Expresso.
Le principe fondamental est d'avoir une table contenant 64 bit qui nous indique si une tâche est exécutable ou pas. De plus,
on classe les tâches en groupes de 8 tâches, ainsi on peut très efficacement déterminer la tâche de plus haute priorité. Nous avons
une variable ReadyGroup qui indique quels groupes contiennent des tâches exécutables. La variable ReadyTable
contient un bit par tâche, ce bit est à 1 quand la tâche est exécutable. Si au moins une tâche du groupe est exécutable, on active
le bit correspondant dans ReadyGroup.
Pour déterminer la tâche de plus haute priorité, il faut déterminer quelle est la tâche dont le numéro de priorité est le plus
faible (càd qui a la priorité la plus élevée) et dont le bit est à 1 dans ReadyTable. Les 3 bits de poids faible d'un numéro
de priorité sont utilisés pour déterminer la position dans ReadyTable et les 3 bits suivants permettent de déterminer
l'index dans ReadyTable et la position du groupe dans ReadyGroup (voir Fig ![]() ).
).
Nous avons aussi besoin de deux tables qui permettent de transformer un index en masque et inversément :
Donc pour rendre une tâche exécutable, on exécute :
![\fbox{\begin{minipage}{7,8cm}
\begin{footnotesize}
\texttt{ReadyGroup \vert= Map...
...able[prio >> 3] \vert= MapTbl[prio \& 0x07];
}
\end{footnotesize}\end{minipage}}](img48.png)
Pour supprimer une tâche des tâches exécutables, on utilise :
![\fbox{\begin{minipage}{10cm}
\begin{footnotesize}
\texttt{if ((ReadyTable[prio >...
... \&= \textasciitilde MapTbl[prio >> 3];\\
\}}
\end{footnotesize}\end{minipage}}](img49.png)
Enfin, pour déterminer la tâche de plus haute priorité, on exécute :
![\fbox{\begin{minipage}{5cm}
\begin{footnotesize}
\texttt{y = UnMapTbl[ReadyGroup...
...pTbl[ReadyTable[y]];\\
prio = (y << 3) + x;
}
\end{footnotesize}\end{minipage}}](img50.png)
Avec cette structure, le scheduler devient extrèmement simple, il suffit de couper les interruptions, vérifier que l'on
n'appelle pas le scheduler d'une interruption (grâce à intCount qui contient de nombre d'interruption en cours), déterminer
la tâche la plus prioritaire et si celle-ci est différente de la tâche courante, on effectue un changement de contexte avec la
macro SWITCH_TASK() avant de réactiver les interruptions.
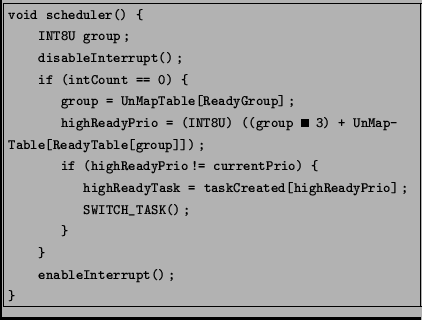
Pour accélérer les calculs lors de la création d'une tâche, on calcule directement les valeurs utiles pour cette structure et on les insère dans le descripteur de la tâche. Ces valeurs sont :
Un changement de contexte consiste simplement à sauver les registres sur la pile de la tâche à suspendre et de restaurer les
registres de la tâche la plus prioritaire qui se trouve sur sa pile. Comme nous l'avons déjà signalé, la pile d'une tâche qui n'est
pas en cours d'exécution ressemble toujours à la pile d'une tâche interrompue, tous les registres de la tâche sont sauvés sur cette
pile. En d'autres termes, pour effectuer le changement de contexte, Expresso doit restaurer les registres et effectuer un retour
d'interruption.
Pour changer de contexte, on génère une interruption avec la macro SWITCH_TASK() qui a pour définition trap 15.
Il suffit de placer l'adresse de notre routine de changement de contexte switchContext() dans la table des vecteurs
d'interruption à la position 15 des traps.
La routine switchContext() a besoin du pointeur vers la tâche de plus haute priorité dans la variable highReadyTask et d'un pointeur vers la tâche courante dans currentTask ainsi que de leurs priorités respectives dans highReadyPrio et currentPrio. Cette fonction est fortement dépendante de l'architecture matérielle et sera expliquée dans la section sur la couche dépendante du matériel.
Dans un système d'exploitation temps réel avec un ordonnanceur préemptif, il est indispensable de disposer d'un mécanisme pour
suspendre une tâche durant un certain nombre de battements d'horloge. Expresso fournit ce service avec la fontion
delayTask()
Précisons rapidement la différence entre un battement d'horloge et une interruption d'horloge. Le battement d'horloge correspond à la fréquence de l'horloge interne. Le timer permet d'envoyer une interruption d'horloge après un certain nombre de battements d'horloge. Le timer est régler pour fournir les interruptions d'horloge à une fréquence définie qui est représentée par la constante HZ. Par défaut HZ = 100, donc il y a 100 interruptions d'horloge par secondes càd toutes les 10 ms.
Le principe est simple, si on veut temporiser une tâche durant 100 interruptions d'horloge, on place la valeur 100 dans le champs
delay du descripteur de la tâche et à chaque interruption d'horloge, on décrémente cette valeur. Dès que cette valeur atteint
0, la tâche devient exécutable.
La routine d'interruption du Timer appelle la fonction processTick qui se charge de décrémenter la valeur delay
des tâches temporisées. Cette fonction est très importante car elle s'exécute à chaque interruption d'horloge, il faut y faire
particulièrement attention pour minimiser son temps d'exécution. Malheureusement pour nous, cette fonction n'est pas déterministe.
En effet, son temps d'exécution dépend du nombre de tâches temporisées dans le système.
La variable time contient le temps depuis que le système tourne en secondes. Donc, dès que le nombre de ticks est égal
à la fréquence, on peut incrémenter time. Ensuite, on parcourt toute la liste des tâches présentes dans le système et on
décrémente le champs delay de chacun si celui-ci est positif. Si après avoir décrémenté delay, sa valeur vaut 0,
il faut réinsérer la tâche dans la structure des tâches exécutables. Pour ce faire, il suffit d'utiliser les commandes vues plus
haut.

La fonction DelayTask commence par vérifier si tick est positif, les interruptions sont désactivées puis
on supprime la tâche de la structure des tâches exécutables, on met à jour le champs delay du descripteur de la tâche.
On termine par activer les interruptions et appeler l'ordonnanceur pour qu'il détermine la tâche la plus prioritaire.
| void delayTask(INT16U tick) | |
| Arguments : | |
| - tick : le nombre de battements d'horloge pour la temporisation | |
Expresso offre aussi une autre fonction delayTaskSec qui permet de temporiser une tâche pendant un certain nombre
de secondes. Cette fonction fait appel à delayTask avec
![]() .
.
| void delayTaskSec(INT16U sec) | |
| Arguments : | |
| - sec : le nombre de secondes pour la temporisation | |
Expresso permet aussi de lire, modifier et effacer la valeur de time qui donne le nombre de secondes qui se sont écoulées depuis le lancement du système d'exploitation ou depuis la dernière modification. Les fonctions qui permettent de faire cela sont :
Expresso possède deux mécanismes de base qui permettent la communication entre différentes tâches : les
sémaphores et les files de messages. Analysons les structures de données et les fonctions nécessaires pour implémenter ces
mécanismes.
1 ère version :
Ces deux mécanismes présentent des points communs qu'il serait intéressant d'utiliser pour concevoir une structure de données
plus générale qui servirait aux deux mécanismes. Le point commun qui saute tout de suite aux yeux est le besoin d'une structure pour
contenir les tâches en attente et pour déterminer laquelle a la plus haute priorité. Le meilleur moyen pour déterminer la tâche
de plus haute priorité est évidemment de reprendre la structure mise en place pour l'ordonnanceur : une table dont chaque bit
indique si une tâche est en attente ou non. Appelons ce mécanisme ITC (Inter Task Communication). Il est possible de regrouper
queuePtr et semCount dans une structure commune (pour améliorer la lisibilité) mais cela complexifie les opérations
sur les sémaphores.
La structure T_ITC va contenir :
2 ème version :
Il y a un petit danger avec la structure précédente. En effet, l'utilisateur qui possède cet objet a tout pouvoir de modifier la
valeur du sémaphore ou directement la valeur d'un message. Ce serait beaucoup moins risqué si cette information était contenue dans
une table externe. Il suffirait juste d'avoir un identificateur qui permettrait de repérer le sémaphore ou la queue. Si on pousse
encore un peu plus loin le raisonnement, il serait même dangereux que l'utilisateur aie accès à la liste des tâches en attente sur
la ressource. Pour éviter cela, il suffirait d'avoir une table contenant toutes les structures T_ITC et de renvoyer un
identificateur lors de la création d'un sémaphore ou d'une liste de message.
Constantes :
Structures concernant les ITC :
Fonctions concernant les ITC :
| void itcInit(ITC_ID id) | |
| Arguments : | |
| - id : l'identifiant de l'ITC | |
ItcInit permet d'initialiser les structures communes aux ITC. Le champs type est placé à la valeur TYPE_NULL, on fait
pointer le pointeur queuePtr vers un élement de type T_QUEUE (voir plus loin), la valeur du sémaphore est placée
à 0 et les listes freeSem et freeQueue sont initialisées.
| void itcReset(ITC_ID id) | |
| Arguments : | |
| - id : l'identifiant de l'itc | |
ItcReset permet d'effacer les champs waitTable et waitGroup de l'ITC id.
| void itcTaskReady(ITC_ID id, void *msg) | |
| Arguments : | |
| - id : l'identifiant de l'itc | |
| - msg : message à placer dans le descripteur de la tâche | |
Cette fonction permet de rendre exécutable la tâche la plus prioritaire en attente sur l'ITC id. On commence par
supprimer la tâche la plus prioritaire de la liste des tâches en attente sur l'ITC puis on la rend exécutable, on réinitialise
le timeout et on place le message dans le descripteur de la tâche. On place le champs status de la tâche à la valeur
READY
| void itcTaskWait(ITC_ID id) | |
| Arguments : | |
| - id : l'identifiant de l'itc | |
La fonction itcTaskWait place la tâche courante en attente sur l'ITC id. Il suffit d'enlever la tâche des
tâches exécutables et de l'insérer dans la liste des tâches en attente sur l'ITC. On place le champs status du descripteur
de la tâche courante à SEM_WAIT ou QUEUE_WAIT en fonction du type de l'ITC.
| void itcTimeOut(ITC_ID id) | |
| Arguments : | |
| - id : l'identifiant de l'itc | |
La fonction itcTimeOut supprime la tâche courante de la liste des tâches en attente sur l'ITC, cette fonction est
utilisée lorsqu'un timeout expire. On place le status de la tâche à READY
| void itcChangePrio(ITC_ID id,INT8U oldPrio,INT8U newPrio) | |
| Arguments : | |
| - id : l'identifiant de l'itc | |
| - oldPrio : l'ancienne priorité | |
| - newPrio : la nouvelle priorité | |
La fonction itcChangePrio permet de changer la priorité d'une tâche qui est en attente sur un ITC. On enlève la tâche de priorité oldPrio de la liste des tâches en attente et on insère la tâche de priorité newPrio dans cette liste.
Comme l'utilisateur n'a pas accès à la table des ITC, il n'aurra pas accès à la valeur du sémaphore qui est stockée directement dans la structure T_ITC
Structure concernant les sémaphores :
Fonctions concernant les sémaphores :
| ITC_ID semCreate(INT16U count, INT8U *err) | |
| Arguments : | |
| - count : la valeur du sémaphore | |
| - err : le code d'erreur | |
| Valeur de retour | |
| - ITC_ID : identifiant du nouveau sémaphore | |
La fonction semCreate permet de créer un sémaphore et d'initialiser sa valeur à count. Si il reste encore des
sémaphores, on enleve un de la liste, on appele itcReset et on renvoie son identifiant. Si il ne reste plus de sémaphore,
err vaudra ERROR_NO_MORE_SEM.
| INT8U semWait(ITC_ID id, INT16U timeout) | |
| Arguments : | |
| - id : identifiant du sémaphore | |
| - timeout : la valeur du timeout | |
| Valeur de retour | |
| - ERROR_NOT_SEM : mauvais identifiant de sémaphore | |
| - ERROR_PEND_ISR : appel du sémaphore dans une interruption | |
| - ERROR_TIMEOUT : le timeout a expiré | |
| - NO_ERROR : aucune erreur | |
La fonction semWait effectue une opération wait sur le sémaphore id avec un timeout. On commence par vérifier
que l'id est bien un sémaphore et que l'on ne se trouve pas dans une interruption. En effet, il est interdit d'effectuer
un wait sur un sémaphore dans une routine d'interruption car cet appel peut bloquer la tâche en cours. Ensuite si la valeur du
sémaphore est positive, on la décrémente et on renvoie NO_ERROR. Sinon, on active le timeout et on appelle itcTaskWait
puis on réactive les interruptions et on fait un appel à scheduler. Cette appel va changer la tâche en cours car
itcTaskWait a supprimé la tâche en cours des tâches exécutables. Ensuite, dès qu'une opération signal sera effectuée, la
tâche qui a effectuée le wait reviendra ou elle était, càd dans la fonction semWait. Si il y a eu un timeout, on renvoie
ERROR_TIMEOUT, sinon, on renvoie simplement NO_ERROR.
| INT8U semSignal(ITC_ID id) | |
| Arguments : | |
| - id : identifiant du sémaphore | |
La fonction semSignal effectue une opération signal sur le sémaphore id. On vérifie si l'identifiant est
bien un identifiant de sémaphore puis si aucune tâche n'est en attente sur le sémaphore, on incrémente sa valeur en vérifiant qu'il
ne soit pas déjà à sa valeur maximum (65535 vu que l'on représente la valeur sur 16 bit) si c'est le cas, on renvoie
ERROR_SEM_OVF. Si au moins une tâche est en attente, on fait un appel à itcTaskReady qui rend exécutable la
tâche la plus prioritaire en attente sur le sémaphore puis on fait appel à scheduler.
| INT8U semRemove(ITC_ID id) | |
| Arguments : | |
| - id : identifiant du sémaphore | |
| Valeur de retour | |
| - ERROR_NOT_SEM : mauvais identifiant de sémaphore | |
| - NO_ERROR : aucune erreur | |
La fonction semRemove permet de supprimer le sémaphore id. On vérifie si l'identifiant est bien un
identifiant de sémaphore puis on force le timeout des tâches en attente sur le sémaphore. Enfin, on réinsère le sémaphore dans la
liste des sémaphores libres et on fait un appel itcReset pour effacer les champs de la structure ITC associée.
| INT16U semCount(ITC_ID id, INT8U *err) | |
| Arguments : | |
| - id : identifiant du sémaphore | |
| - err : le code d'erreur | |
| Valeur de retour | |
| - la valeur du sémaphore | |
La fonction semCount permet d'obtenir la valeur du sémaphore id. On vérifie si l'identifiant est bien un
identifiant de sémaphore puis on renvoie simplement sa valeur. Si l'identifiant n'est pas un identifiant de sémaphore, err
vaudra ERROR_NOT_SEM
Structure concernant les files de messages :
Fonction concernant les files de messages :
| ITC_ID queueCreate(void **start, INT16U size, INT8U *err) | |
| Arguments : | |
| - start : pointeur vers le début de la file de messages | |
| - size : la taille de la file | |
| - err : le code d'erreur | |
| Valeur de retour | |
| - l'identifiant de la file de messages | |
La fonction queueCreate permet de créer une file de messages. On vérifie qu'il reste encore une file disponible sinon
on renvoie ERROR_NO_MORE_QUEUE. Ensuite on retire la file de la liste des files libres et on initialise ses différents
champs start = start, end = &start[size], first = start, last
= start, size = size et count = 0.
| void *queueWait(ITC_ID, INT16U timeout, INT8U *err) | |
| Arguments : | |
| - id : identifiant de la file | |
| - timeout : la valeur du timeout | |
| - err : le code d'erreur | |
| Valeur de retour | |
| - un pointeur vers un élement de la queue. | |
La fonction queueWait permet de recevoir un message mais avant une durée fixée par un timeout. On vérifie que
l'identifiant est bien une file et que l'on n'est pas dans une interruption puis si la file n'est pas vide, on renvoie le premier
message qu'elle contient, on décrémente le compteur de message et on augmente le pointeur de message first. Sinon on
enclenche le timeout, on fait un appel à itcTaskWait pour placer la tâche en cours en attente sur la file et on lance
l'ordonnanceur avec scheduler. Dès qu'un message arrive, la tâche la plus prioritaire qui est en attente reprend
l'exécution. On vérifie alors que le timeout n'a pas expiré dans ce cas on renvoie ERROR_TIMEOUT. Sinon, on renvoie
le premier message de la liste qui est contenu dans le champs msg du descripteur de la tâche.
| INT8U queueSend(ITC_ID id, void *msg) | |
| Arguments : | |
| - id : identifiant du sémaphore | |
| - msg : le message à envoyer | |
| Valeur de retour | |
| - ERROR_NOT_QUEUE : mauvais identifiant de sémaphore | |
| - ERROR_QUEUE_FULL : la file est pleine | |
| - NO_ERROR : aucune erreur | |
La fonction queueSend envoie un message dans la file. Si une tâche est en attente sur la file, on appel
itcTaskReady pour rendre exécutable la tâche la plus prioritaire en attente sur la file en lui passant le message que l'on
veut envoyer puis on appelle scheduler. Si aucune tâche n'est en attente sur la file, on insère le message dans la file, si
celle-ci est pleine, on renvoie ERROR_QUEUE_FULL.
| void* queueReceive(ITC_ID id) | |
| Arguments : | |
| - id : identifiant de la file | |
| Valeur de retour | |
| - un pointeur vers le message si il y en a un et NULL sinon. | |
La fonction queueReceive permet de prendre un message de la file sans attendre. Si la file est vide on renvoie NULL,
sinon on renvoie le premier message.
| INT16U queueCount(ITC_ID id, INT8U *err) | |
| Arguments : | |
| - id : identifiant de la file | |
| - err : le code d'erreur | |
| Valeur de retour | |
| - le nombre de messages dans la file. | |
La fonction queueCount renvoie le nombre d'élements dans la file de message id.
| INT8U queueReset(ITC_ID id) | |
| Arguments : | |
| - id : identifiant de la file | |
| Valeur de retour | |
| - ERROR_NOT_QUEUE : mauvais identifiant de file de messages | |
| - NO_ERROR : aucune erreur | |
La fonction queueReset permet d'effacer le contenu de la file.