Challenge 4: Forking Prevention¶
While exploring operating system concepts, you encountered a mysterious executable named “forking”. Intrigued by the name, you downloaded the file to examine its behavior. However, rather than executing it immediately, you chose to proceed cautiously, recognizing the risks associated with running unverified binaries.
To better understand its behavior, you analyzed the program and discovered that
it repeatedly invokes fork() to create a large number of child processes in
a short period of time. Left unchecked, this could overwhelm your system with
too many processes and lead to a denial of service.
To mitigate this, you decide to instrument the system using eBPF. This approach allows you to observe and control process creation directly in the kernel, enabling you to detect and regulate process creation without modifying the user-space program itself.
Description¶
The “forking” program operates as follows:
It repeatedly calls
fork()in a loop to create child processes. The time between two consecutivefork()calls is random, bounded by a configurable maximum (set via a#definemacro in the source code).Each child process simulates a workload by sleeping for a fixed duration before exiting.
At the end of execution, the parent process waits for all child processes to terminate before exiting itself.
The number of children to create is also hardcoded as a
#definemacro (set to 100 by default).
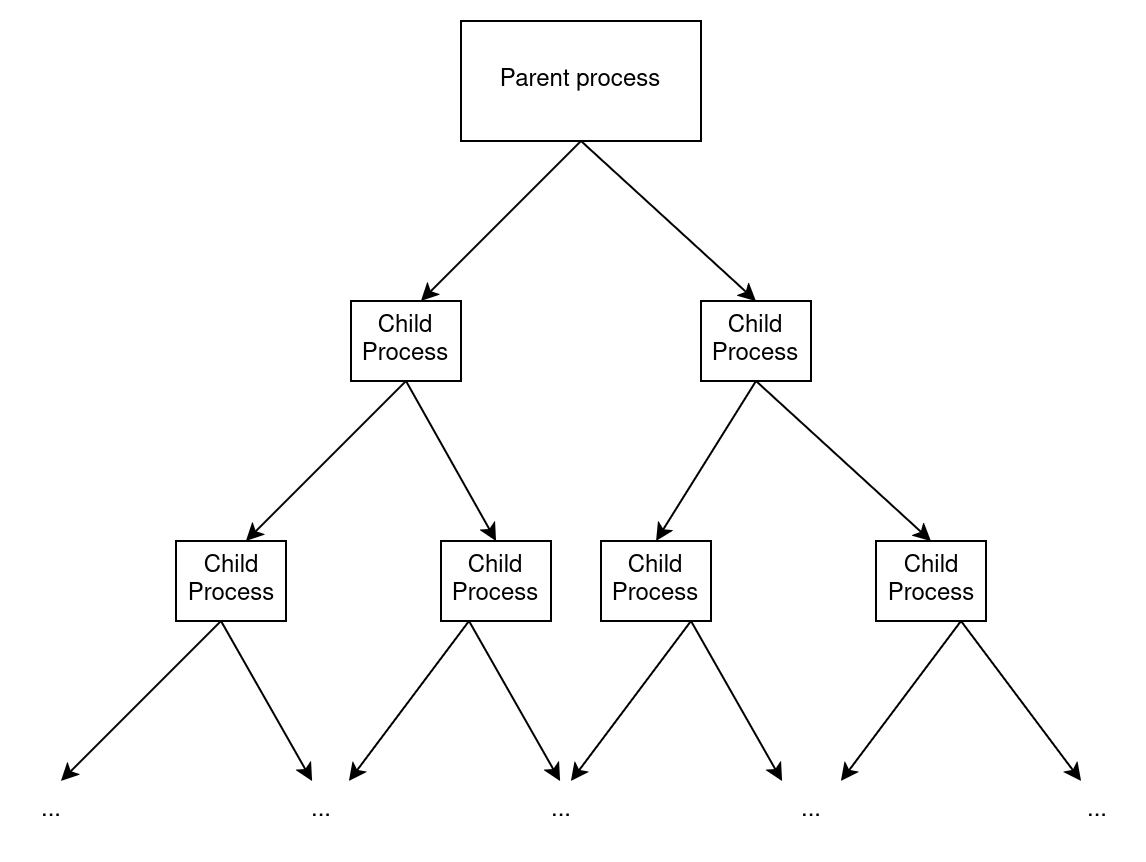
The resulting structure is a single-level process tree, where only the main process forks children, as illustrated below.
Note
You may modify the #define macros in the source code of the
“forking” program if needed for testing purposes, but it should not be
necessary for your solution.
Important
Internally, fork() uses the clone syscall on Linux. Your
eBPF program will need to hook into this syscall.
The Policy¶
Your eBPF program must enforce the following rate-limiting policy on the “forking” process: a child process is killed if the time difference between its creation and the creation of the child n positions before (in the list of successfully created children) is less than t seconds.
Example with t = 1s and n = 5 where child 25 is killed:
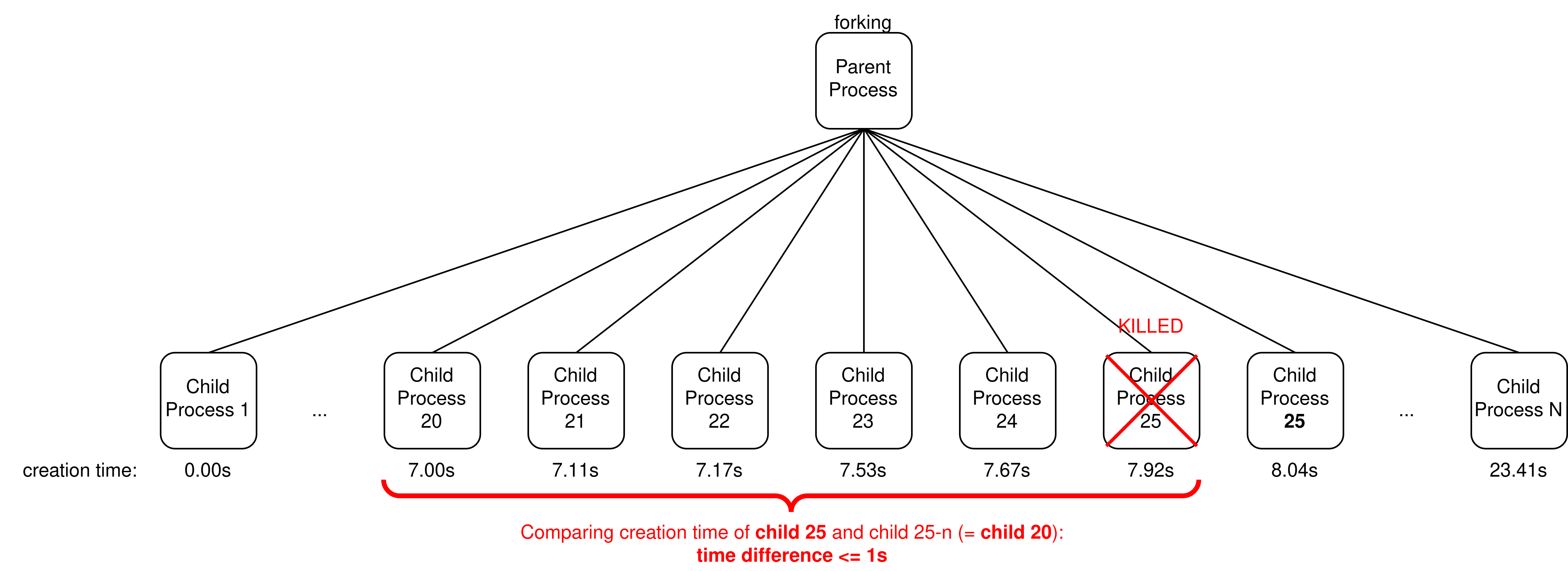
Note that since child 25 has been killed, the next child to be created is considered child 25 again and not 26. Its creation time is thus still compared to child 20 and not child 21.
Example with t = 1s and n = 5 where child 25 is successfully created:
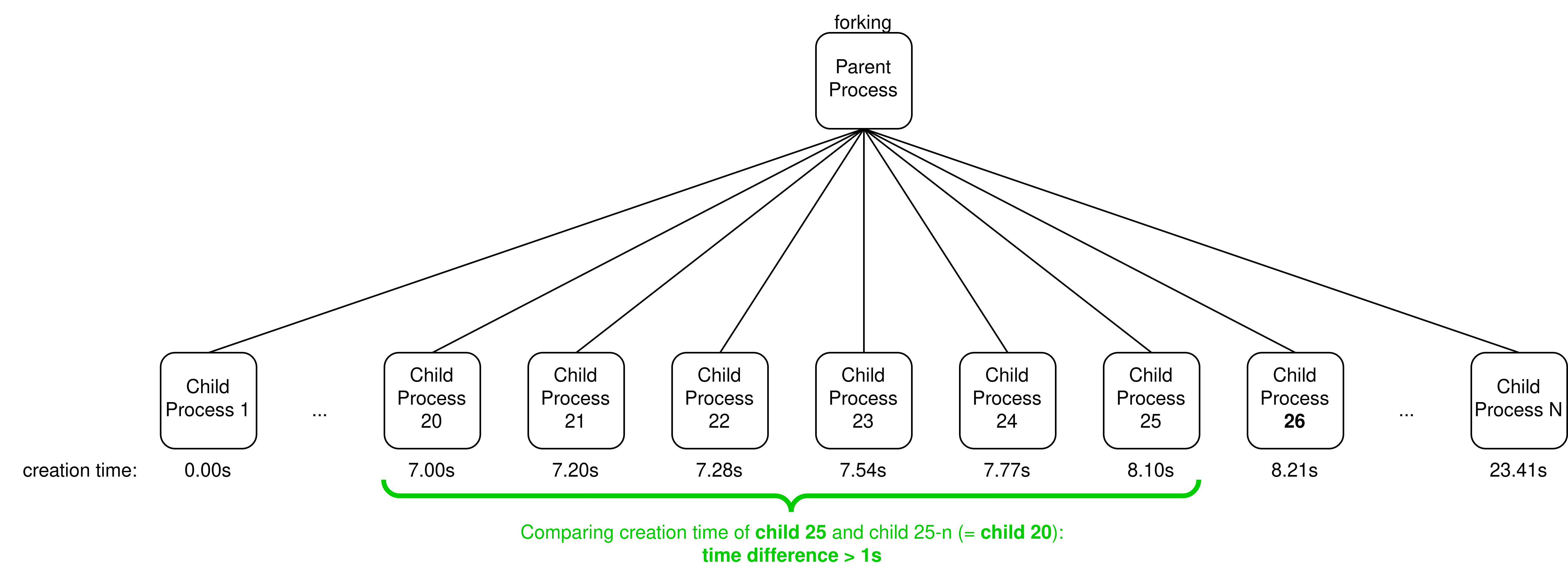
Important
Your eBPF program must not interfere with the rest of the system. You must filter by process name: only children of a process named “forking” should ever be targeted.
Another way to see it is that your eBPF program maintains a sliding window of the last n children created by the parent. Each time a new child is created, it checks whether the time elapsed between this new child and the oldest child in the window (i.e. n children ago) is less than t seconds. If it is, the new child is killed. Otherwise, it is allowed to live and becomes part of the window.
Here is a concrete example of the bootstrapping phase of the window filling process, again with n = 5 and t = 1 second:
Children 0 through 4 are always allowed (the window is not yet full when they arrive). No comparison is made yet since there is no child to evict from the window in order to make them enter. (The other way to see it is that there is no child that is 5 positions behind them.)
When child 5 is created, the program compares its creation time with that of child 0. If the difference is less than 1 second, child 5 is killed. Since child 5 was killed, it is not added to the window.
When the parent tries to create another child (what would have been child 6), it is again compared against child 0 (still the oldest in the window), since child 5 was killed and never entered the window.
This continues until a child survives (i.e. it was created more than t seconds after the oldest child in the window), at which point it enters the window and child 0 is evicted.
Setup¶
Download the files for this challenge using:
$ wget --no-check-certificate https://people.montefiore.uliege.be/~gain/courses/info0940/asset/fork.tar.gz
$ tar -xzvf fork.tar.gz
The “forking” program is located in fork/forking. You can compile it
using the Makefile provided (simply run make within the forking/
directory). Then run it using:
$ ./forking
Inside forking/src, you will find the same template as in tutorial 3. Use
it to implement your eBPF program.
What you need to do¶
Implement an eBPF program that enforces the policy described above. The values
of n and t must be configurable from the command line when loading the eBPF
program, using the following arguments in prog.c:
--n_process: The size of the sliding window, i.e. how many recent children to track. Default should be 1. The maximum allowed value is 32.--time_separation_sec: The minimum time in seconds that must separate the current child from the one created n children ago. Default should be 1 second.
Note
Your solution will only be tested with a single instance of the “forking” program running at a time. You do not need to handle the case where multiple instances run concurrently.
For example, with the following command:
$ sudo ./prog --n_process 1 --time_separation_sec 1
Running the “forking” program should produce output similar to this (PIDs will vary):
$ ./forking
Main process PID 4846 starting, creating 100 children
- Child process created with PID 4847 (parent 4846)
- Child process created with PID 4852 (parent 4846)
- Child process created with PID 4856 (parent 4846)
- Child process created with PID 4860 (parent 4846)
- Child process created with PID 4864 (parent 4846)
- Child process created with PID 4867 (parent 4846)
- Child process created with PID 4873 (parent 4846)
- Child process created with PID 4877 (parent 4846)
- Child process created with PID 4881 (parent 4846)
- Child process created with PID 4884 (parent 4846)
- Child process created with PID 4888 (parent 4846)
- Child process created with PID 4892 (parent 4846)
- Child process created with PID 4898 (parent 4846)
- Child process created with PID 4903 (parent 4846)
- Child process created with PID 4908 (parent 4846)
- Child process created with PID 4915 (parent 4846)
- Child process created with PID 4919 (parent 4846)
- Child process created with PID 4923 (parent 4846)
- Child process created with PID 4930 (parent 4846)
- Child process created with PID 4937 (parent 4846)
- Child process created with PID 4940 (parent 4846)
- Child process created with PID 4945 (parent 4846)
Main process PID 4846 waiting for children to finish...
As you can see, only 22 child processes were created successfully, while the rest were killed by your eBPF program for violating the rate-limiting policy.
Choosing n = 1 and t = 1 second should result in printing approximately one line per second, since each child must be created at least 1 second after the previous one. You can experiment with different values of n and t to see how they affect the output.
Tip
The eBPF verifier tends to be less strict when using a BPF_MAP_TYPE_ARRAY keyed by a runtime index than when indexing into an array field of a map value struct.