eBPF Basics (Part 1)¶
In this tutorial, you will learn the basics of eBPF (extended Berkeley Packet Filter). eBPF is a technology that allows you to run sandboxed programs in the Linux kernel.
The second project of this course will be to write a series of eBPF programs. This tutorial will help you to understand the basics of eBPF and how to write eBPF programs using the libbpf library.
How to modify the Linux kernel¶
The Linux kernel is an open-source and free (free as in freedom, not as in free beer 🍺) operating system kernel. Therefore, you are free to modify the Linux kernel on your machine (or Virtual Machine) as you wish.
Modifying the kernel can be a fun way to learn more about the Linux kernel and how it works. The privileged nature of the kernel can also be leveraged to implement observability, security, and networking functionality. Companies like Google, Facebook, or Amazon modify the Linux kernel to fit their needs.
There are three conventional ways to run our code in the kernel or modify its behavior:
Modify the kernel source code and recompile the kernel
Write a kernel module and load it into the kernel
Write an eBPF program and load it into the kernel
The kernel is a very complex and large codebase. Therefore, whatever the way you choose to modify the kernel, it will not be an easy task. However, eBPF tries to make this task easier by providing a simple and safe way to run programs in the kernel.
Important
When you will write kernel code, you will not be able to use the
standard C library (libc) or the standard C headers. You will need to use
other headers and libraries provided by the kernel. For example, to compare
two strings in an eBPF program, you will use bpf_strncmp instead of
strncmp. This is because the kernel is not a user-space program and does
not have access to the same resources as a user-space program.
eBPF Overview¶
eBPF is a technology that allows you to run sandboxed programs in the Linux kernel at runtime. It was introduced in 2014, where it was mainly used for networking purposes. Since then, eBPF has been extended to other parts of the kernel, such as tracing, security, and observability.
You can write a program, compile it to eBPF bytecode, and load it into the kernel. Your bytecode will be executed with the help of a Just-In-Time (JIT) compiler.
A verification engine will also check that your bytecode is safe to run in the kernel (ensures memory safety, prevents loops that might not terminate, etc.). This is important because a bug in your program could crash the kernel or compromise the security of the system. This, combined with the sandboxing, means that your code will need to abide by a set of rules to be accepted by the kernel. In addition, you will not be able to directly use all the features of the kernel in your eBPF program, but will be using helper functions instead.
In your program, you will set up hooks to run your eBPF program in kernel mode when a specific event occurs.
The libbpf Library¶
Developing eBPF programs involves two parts: the kernel-space eBPF code, and user-space code that loads the eBPF program into the kernel and interacts with it. libbpf is the standard, low-level C library maintained alongside the Linux kernel itself for building both of these components. The kernel-space components are helpers that make it easier to write eBPF programs, while the userspace components help for loading them and interacting with loaded resources.
Project Layout¶
A typical libbpf project contains two files:
prog.bpf.c— the eBPF kernel-space code that will be compiled to eBPF bytecode and loaded into the kernel. This is where you will write your eBPF program.prog.c— the user-space loader that opens, loads, attaches, and polls your eBPF program. These operations are already given to you so you won’t have to modify this file for today’s tutorial. However you will need to modify it for tutorial 4 and project 2.
Installing Dependencies¶
You will need clang (to compile the BPF object), libbpf development headers, and bpftool (to generate the vmlinux.h header). Install them with:
$ sudo apt install clang libelf-dev zlib1g-dev libbpf-dev linux-tools-$(uname -r)
Note
bpftool is part of the linux-tools-* package. If the
versioned package is unavailable, linux-tools-generic usually provides
a working binary.
You then need to build and install libbpf from source. You can do this by running the following commands:
$ git clone https://github.com/libbpf/libbpf.git && cd libbpf/src
$ make && sudo make install
Template¶
To simplify development, we will provide you with a template that contains a
Makefile, a C file (for user-space) and a bpf.c file. For today’s tutorial, you can download it and
decompress it using:
$ wget --no-check-certificate https://people.montefiore.uliege.be/~gain/courses/info0940/asset/eBPF_template.tar.gz
$ tar -xzvf eBPF_template.tar.gz
In the template, you will find a Makefile to compile the eBPF program and a
bpf.c file that will contain your code. Right now, it contains two include
directives and it defines a license; you don’t need to modify these lines. We
are going to complete this template in following sections.
The vmlinux.h Header¶
With libbpf, instead of including kernel headers manually (which can be fragile
across versions), you generate a single vmlinux.h file that contains all
kernel type definitions for your currently running kernel:
$ bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
Note
This step is already included in the Makefile of the template.
This file is included at the top of your .bpf.c file and replaces the need
for scattered kernel headers.
Hooks¶
As mentioned above, your eBPF program will be executed when a specific event occurs. These events are called hooks. For example, you can set up a hook to run your eBPF program when a network packet is received.
There are different types of hooks: system calls, function entry/exit, kernel tracepoints, network events, etc.
Today, we will focus on two types of hooks: system calls and uprobes. Next week, other types of hooks will be introduced.
To define a hook in your eBPF program, you will need to use the SEC macro
provided by libbpf. Understanding how this macro works is not crucial for
the project, but here is a brief explanation:
(facultative explanation) On Linux, executables use the ELF format which contains sections used to store different types of data or code. For example, the
.textsection generally contains most of the executable code, the.datasection contains the initialized data, etc.In eBPF, custom sections are defined to indicate how to treat the code or data in these sections. For example, you can find a section called
tracepoint/syscalls/sys_enter_writethat indicates the code to run when the syscallwriteis called.libbpfuses theSEC(section_name)macro to define a new section namedsection_namein the eBPF program.Note
You can use
readelf -W -S prog.bpf.oto see the sections of the compiled eBPF program. After adding a hook in your eBPF program and compiling it (what we will do in the next section), you should see a new section in the output of the command.
What you need to know is that when you want to define a hook in your eBPF
program, you will need to use the SEC macro before your function
definition. You can find a list of well-known program sections to use with the
SEC macro here.
Let’s move to the next section to see how to use the SEC macro to define a
hook in your eBPF program.
System calls hooks¶
Let us first recall what a system call is.
System calls are the interface between user-space and kernel-space.
Indeed, without using system calls, user-space programs are tied to their (virtual) address space and can only use unprivileged instructions on the CPU (e.g., they can declare variables, make calculations, jump to other parts of their code, etc.).
If they want to interact with the hardware, with other processes or access (other) kernel’s services, they need to use system calls. They will then be able to read/write files, create processes, communicate with other processes, etc.
Note
For example, the user-space program that will load your eBPF program
into the kernel will use the bpf system call to do so. You can find a
list of system calls used in the x86 architecture at
/arch/x86/entry/syscalls/syscall_64.tbl
in the kernel source code.
Let’s now use the SEC macro to define a hook on a system call. The syntax is:
// (inside the bpf.c file before the function definition)
SEC("tracepoint/syscalls/sys_enter_<syscall_name>")
If you want your code to execute after the system call, you can use:
// (inside the bpf.c file before the function definition)
SEC("tracepoint/syscalls/sys_exit_<syscall_name>")
Note
Tracepoints are predefined hooks in the kernel that allow you to execute code when a specific event occurs.
For example, add this code in your prog.bpf.c file (after the
“Place your code here” comment) to define a hook that will be executed when the
execve system call starts:
SEC("tracepoint/syscalls/sys_enter_execve")
int handle_hook(struct trace_event_raw_sys_enter *ctx)
{
return 0;
}
Using the SEC macro, you indicated that your handle_hook function
should be executed when the execve system call starts (You could have
chosen another name for the function). The function you used to hook a syscall
will always need to return 0, and will take a parameter of type struct
trace_event_raw_sys_enter *. This parameter contains information about the
system call that is being hooked.
You can then use the make command to compile your code:
$ make
bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
clang -O2 -g -Wall -target bpf -D __TARGET_ARCH_x86 -c prog.bpf.c -o prog.bpf.o
cc -O2 -g -Wall prog.c -o prog -lbpf -lelf -lz
The make command also generated the vmlinux.h header and compiled the
user-space loader (prog.c) that will load your eBPF program into the
kernel.
You can then run the user-space loader with root privileges to load your eBPF program into the kernel:
$ sudo ./prog
Currently, the handle_hook function does nothing, but you can use the
following command (in another terminal inside your VM) to see that your eBPF
program is running:
$ sudo bpftool prog show
# [...] You should see other eBPF programs here, then you should see your
# eBPF program at the end of the list looking something like this:
30: tracepoint name handle_hook tag a04f5eef06a7f555 gpl
loaded_at 2026-03-05T16:38:48+0000 uid 0
xlated 16B jited 20B memlock 4096B
btf_id 87
To stop the program, press Ctrl+C (in the terminal where you ran the
./prog command). The user-space code cleans up and unloads the eBPF
program from the kernel automatically. (You can check that the program is no
longer running by running the sudo bpftool prog show command again.)
Uprobe hooks¶
Hooks are not limited to kernel events such as system calls. You can also set up hooks on user-space events. This means that when a specific user-space function is called, your eBPF program will be executed (in the kernel).
You can place hooks at the beginning, end, or at a specific address of a function. To place a hook, you need to specify:
the name of the function you want to hook (or its address).
the path of the binary which contains this function.
When your uprobe is registered, its effect is (almost) immediate on all the processes that have been and that will be instantiated from the binary you are hooking.
For example, to add an uprobe on the readline function of the bash
binary, you can use the following code:
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
// ...
SEC("uprobe//usr/bin/bash:readline")
int BPF_UPROBE(my_probe, const char *prompt)
{
// your code here
return 0;
};
BPF_UPROBE is a
macro that will take as first argument the name of the function that will be
executed when the uprobe is hit (my_probe in this case; you can name it
however you want). The remaining arguments correspond to the parameters of the
function being hooked. In this case, the readline function’s prototype is
char *readline(const char *prompt).
Knowing how uprobes internally work is not crucial for the project, but here is a brief explanation:
Note
To fully understand this explanation, you will need to know about inodes and File Control Blocks (Chapter 11: Implementing File Systems) and virtual memory (chapters 6 and 7).
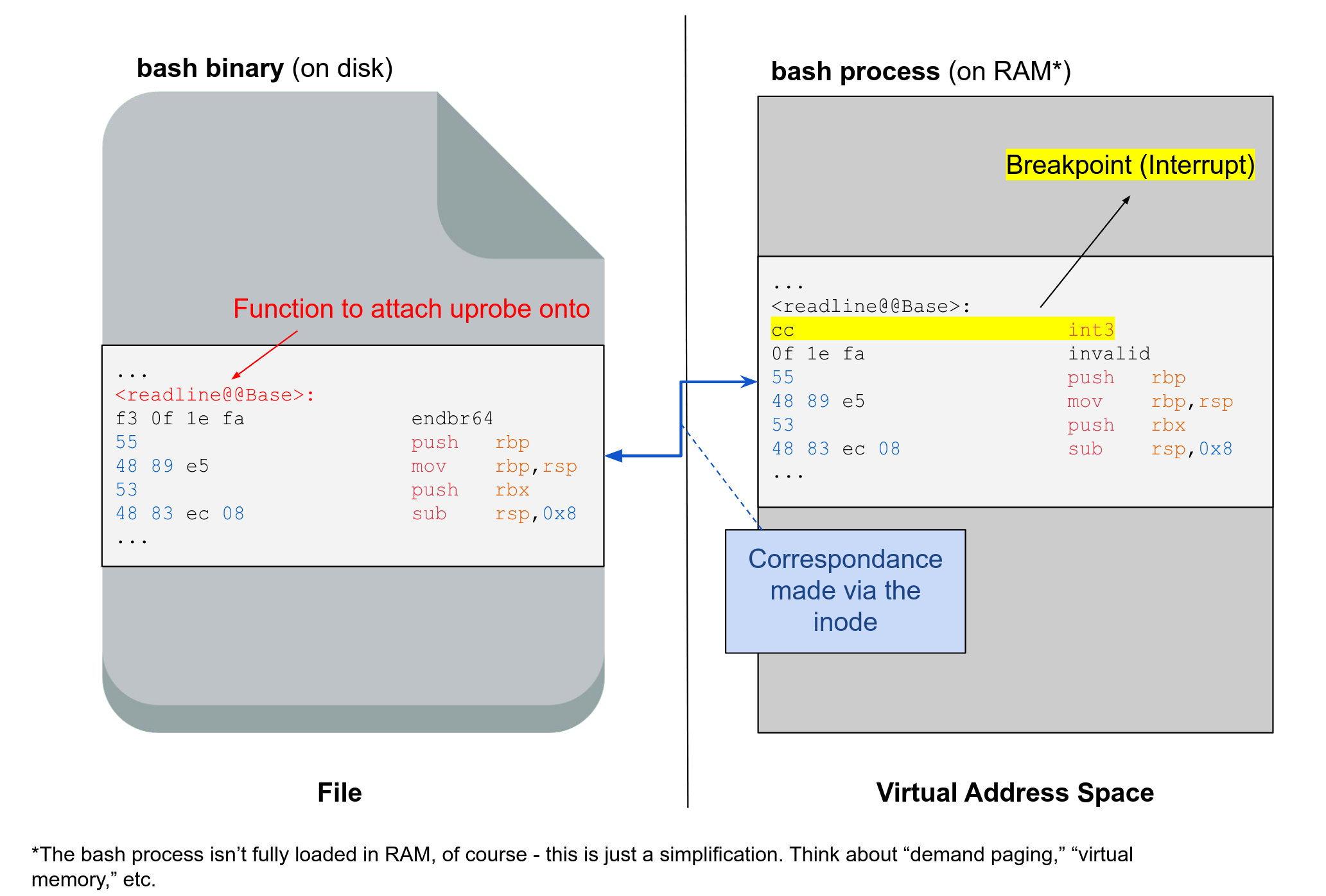
Uprobe hook (facultative explanation)¶
(facultative explanation) When you set up a uprobe, the kernel uses the inode of the binary to locate it in memory and determine where to place the breakpoint (described below).
Important
The inode is the Linux equivalent of the FCB (File Control Block), which you learned about in the theoretical part of the course. You can consider that they represent the same thing. Please remember both terms for the exam.
(facultative explanation) To be able to execute your eBPF code when the uprobe is hit, a breakpoint is placed at the beginning of the function you are hooking. This breakpoint is placed in the virtual address space of the process, not in the code within the program on the disk. The breakpoint is a software interrupt (
int3, opcode is0xCC). The interrupt handler will restore the instruction that was replaced by the breakpoint and make sure to execute your eBPF code when needed.
Helper Functions¶
To avoid compatibility issues with different kernel versions, eBPF programs cannot directly call kernel functions. Instead, they use helper functions that are provided by the kernel. You will therefore need to use helper functions to perform specific tasks in your eBPF program like printing a message, reading from a specific data structure called maps (that will be introduced next week), get information about a process, etc.
Here is the documentation of helper functions.
For example, let’s use the bpf_printk helper function to print a message in
the kernel logs. Add the following line to the handle_hook function:
bpf_printk("Hello, World!\n");
Note
The bpf_printk is very simple to use but cannot be used
to exchange data between user-space and kernel-space. It is only
useful for debugging purposes. Next week, you will learn how to use
maps to exchange data between user-space and kernel-space.
You can then compile and run your program as explained above. You can access the kernel logs by running the following command:
$ sudo cat /sys/kernel/debug/tracing/trace_pipe
Now, you should see the message Hello, World! in the kernel logs.
If you try to open new terminals or launch a new process, you will see that new
Hello, World! messages are printed in the kernel logs. This is because the
execve system call is called when a new process is executed.
Another helper function that you will probably need in the project is the
bpf_get_current_pid_tgid function. This function returns the PID and the
TID of the current task. For example, to get the pid of the process that called
the execve system call, you can use:
pid_t pid = bpf_get_current_pid_tgid() >> 32;
Important Resources¶
If you want an overview of eBPF, you can check the following website (reexplains what was said above, and more): https://ebpf.io/what-is-ebpf/
To find out the different hooks, helper functions, etc available, check the eBPF documentation: https://docs.ebpf.io/ or the kernel side documentation (which sometimes contains more information).
The libbpf API documentation and usage guide will be very useful: https://libbpf.readthedocs.io/
The libbpf-bootstrap repository provides minimal project skeletons and examples to get started quickly: https://github.com/libbpf/libbpf-bootstrap
If you want to hook specific kernel functions, you will maybe need to check the kernel source code and/or the kernel documentation of kernel 6.8 (which is the kernel you use in the VM).
Summary: The Life Cycle of an eBPF Program¶
Here is a summary of the life cycle of an eBPF program:
Write your eBPF kernel code in C (prog.bpf.c).
Compile it to BPF bytecode using clang.
Write a user-space loader (prog.c) that uses libbpf to open, load, and attach your eBPF program.
Run the loader with root privileges (sudo ./prog). Your eBPF program will then execute in kernel mode whenever the hooked event occurs. It will use helper functions to use kernel features and will communicate with user-space via the kernel logs (you will learn better ways to communicate with user-space next week).
Unload your eBPF program by stopping the loader with Ctrl+C. The loader detachs and unloads the program automatically.
Notions that you might come across¶
BPF vs eBPF: eBPF stands for extended BPF. BPF (Berkeley Packet Filter) was introduced in 1992 and was used to filter packets in the kernel. eBPF was introduced in 2014 and extended BPF to allow you to run sandboxed programs in the kernel. Since eBPF is not limited to networking anymore, the acronym does not really make sense anymore.
Note
In the kernel documentation/source, “BPF” is sometimes used to refer to eBPF.
CO-RE: Compile Once, Run Everywhere. It simply means that you can compile your eBPF program once and run it on different kernels.